现代Fortran程序设计
作者:Fortran-Fans
序言
欢迎学习和使用Fortran!Fortran是一门主要应用于高性能数值计算与科学计算的程序语言,其特色在于灵活且强大的数组特性、易于编写并行数值算法。
关于Fortran
我们不打算在这里过多介绍Fortran的历史——毕竟你能很容易通过搜索引擎了解到。Fortran是一门「古老」的语言,古老到即使你以前未曾学习过Fortran,也可能听过别人对于古早Fortran代码的吐槽。但是Fortran也是一门「新」语言,因为新的语言标准仍在发布。Fortran的最新标准是Fortran 2018,下一个版本Fortran 202X也正在讨论中。
虽然Fortran属于「通用程序语言」[wikipedia],但是其主要应用的领域是数值计算。Fortran内置支持创建和使用数组,而且具有积累悠久的数值算法库,使得用户能轻松地编写数值计算程序。作为强类型语言,编译时对过程接口的严格检查,也保证了Fortran程序计算结果的可靠性。此外,Fortran具有良好的并行性,语法标准即支持了Coarray并行。你也可以通过其他并行API(OpenMP、MPI、CUDA Fortran等)编写并行Fortran程序。
Fortran也有一些缺点:Fortran并不适合编写通用性的应用程序。用Fortran编写GUI程序是比较困难的,也缺少对于计算机底层的直接控制。不过Fortran提供了与C语言交互的接口。在实践中,可以使用其他语言构建程序主体,用Fortran编写计算密集的部分,两者之间通过C语言接口传递数据。
在实际开发中,Fortran还有如下的一些问题。Fortran标准只提供了一些内置过程与模块,并没有标准库。对于一些常用但是标准内并未提供的函数,用户可能要么自己编写实现,要么只能去寻找散落在各处的函数库。将代码构建为可执行程序也并非容易的事,尤其是当使用了其他函数库。如果你使用makefile,你可能需要手动维护源代码之间的依赖关系。
2019年,Ondřej Čertík和Milan Curcic等人建立了fortran-lang社区,并开始了Fortran Standard Library(stdlib)、Fortran Package Manager(fpm)等项目的开发。虽然这些项目尚处于早期版本,但我们已经能窥见到它们的强大之处。尤其是fpm,提供了包管理以及项目构建功能。这使得我们能够方便地复用他人的代码,并构建自己的函数库或程序。
我们希望fortran-lang社区的发展与Fortran标准的进一步演化(比如提供泛型功能)能够使Fortran这门语言继续保持其生命力,让我们能使用Fortran继续开发数值计算程序。
关于本书
不得不承认的一点是,早期Fortran的影响力依然存在,不仅是代码遗产,也包括各种资料与书籍。我们编写这本书的一个目的,就是推广现代Fortran的特性以及开发工具。在这本书中,我们不会讲解任何过时的特性,而是着重于那些更为安全、更为友好的语言特性。
此外,我们希望本书并非单纯讲解Fortran的语言特性。我们认为真正重要的是帮助初学者学会编写程序、学会构建程序。因此本书也会简单介绍一些并非Fortran本身,但是编写程序时经常要接触到的概念与知识。需要注意的是,设计与构建程序框架的范式并非唯一,且各有优劣,所以我们无意也无法介绍所有的范式。本书将主要使用模块化的程序设计——这里的「模块」既表示抽象的功能单元,也表示Fortran的一种语言单元module。
为了让初学者们更加贴近开源社区,本书选择gfortran编译器和fpm作为开发工具进行讲解。我们也希望你能够参与开源社区建设。
我们希望本书能教会你基础的Fortran语法,编写出结构化的程序。如果你在学习和编写Fortran中有任何疑问,欢迎加入「Fortran 初学」群(100125753)提出你的问题。
其他Fortran参考资料
- Modern Fortran - Milan Curcic
- Quickstart Fortran Tutorial - fortan-lang
- Fortran程序设计(第四版) - Stephen J. Chapman
安装Fortran开发环境
本教程使用Msys2-GFortran编译器进行Fortran开发,它的优点有:
- 可以生成Windows本地化执行程序;
- 国人更熟悉Windows环境;
- 方便管理和升级;
- 性能很好。
缺点有:
- 运行时更详细的堆栈错误信息缺失;
- 调试不算方便;
- 可能存在配套工具Windows环境不适应的问题。
即使它有如上缺点,但它仍是一款很强的Fortran编译器,且随着用户的使用和MSYS2的进步,它也会越来越好用。
安装MSYS2-GFortran软件
前往MSYS2官网下载安装MSYS2安装包,并阅读相关文档。
这里列出一些有用的部分命令:
pacman -Syu # 升级msys2内部组件和仓库信息
pacman -Ss <package_name> # 搜索软件
pacman -S <package_name> # 安装软件
pacman -Qs <package_name> # 查询本地安装的特定软件
pacman -Rs <package_name> # 卸载软件
pacman -R --help # 查询命令的帮助文档
...
我们可以通过以下命令安装MSYS2-GFortran:
pacman -Ss fortran # 查询名字中含“Fortran”字符的包
pacman -S ucrt64/mingw-w64-ucrt-x86_64-gcc-fortran # 安装ucrt64版本的gfortran
为了方便我们在MSYS2环境之外使用MSYS2-GFortran,我们需要设置如下环境变量:
C:/msys64/ucrt64/bin # UCRT64环境的二进制可执行程序所在路径
C:/msys64/usr/bin # MSYS2 环境的二进制可执行程序所在路径
我们可以在Windows下的CMD中使用以下命令核对环境变量是否设置正确:
$ gfortran
GNU Fortran (Rev2, Built by MSYS2 project) 11.2.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
🔰 提示:这里默认我们现在大多数使用的硬件是64位的,且使用较新的MSYS2环境(UCRT),有个性化需求可以进行自定义。
fpm基本操作
Fortran Package Manager(fpm)是Fortran-Lang组织主导、为Fortran语言专门定制开发的免费、开源的包管理器和构建系统。
gfortran是Fortran编译器,当项目源代码文件增多时,我们需要依靠Make、CMake、XMake、fpm来管理和 构建项目,这会为我们节约很多构建代码的时间和精力。
我们可以前往fpm仓库获取最新的安装教程和安装包, 并阅读相关文档。
我们也可以通过MSYS2安装fpm:
pacman -Ss fpm # 查询名字中含“fpm”字符的包
pacman -S ucrt64/mingw-w64-ucrt-x86_64-fpm # 安装fpm软件
现在,fpm已经有了面向用户的中文文档网页(fpm.fortran-lang.org)了。
🔰 提示:fortran-lang/fpm不仅支持GFortran,还支持OneAPI和LFortran等其他Fortran编译器。
创建fpm项目演示
我们可以搭配命令行终端(cmd、pwsh、bash、fish)使用fpm,使用vs code编辑代码:
fpm new hello_world && cd hello_world # 新建FPM项目并切换到文件夹下: hello_world
fpm build # 编译FPM项目
fpm run # 运行主程序🚀
fpm test --help # 获取特定命令行参数的帮助文档
code . # 使用VS Code打开当前文件夹
...
🔰 提示:
fpm build类似Visual Studio的Debug模式,fpm build --profile release类似Visual Studio的Release模式。
第一个Fortran程序
本章会讲解一个简单的小程序,一方面能让你继续熟练使用你的编程环境,另一方面是让你对Fortran有初步的了解。
我们会尽可能详细地讲解每一行代码的含义,但是请放心,如果你对理解特定语句暂时感到困难,请直接跳过。通过后续章节循序渐进地学习,你最终还是可以学会相关语法。
讲解前的准备
在命令行中执行fpm new first-fortran创建新项目。在fpm项目的src目录中新建名为Stern_Gerlach_experiment.f90的文件(别忘了删除默认生成的.f90文件),并将以下内容写到该文件中:
module Stern_Gerlach_experiment
implicit none
private
public :: emit_atom
contains
subroutine emit_atom()
real :: raw_number
integer :: spin ! 0代表spin up,1代表spin down
call random_number(raw_number) ! raw_number的范围是[0,1)
spin = nint(raw_number) ! 四舍五入得到0或1
if (spin == 0) then ! 判断spin的值,若等于0,则执行下面语句
write (*, *) "Emit an atom with spin up."
else ! 否则执行这一部分
write (*, *) "Emit an atom with spin down."
end if
end subroutine
end module
接下来修改app中的main.f90,将其中的内容改为:
program main
use Stern_Gerlach_experiment ! 引入模块,从而能够使用其中定义的变量及过程
implicit none
integer, parameter :: emission_times = 5 ! 实验的观察次数
integer :: i
do i = 1, emission_times
call emit_atom()
end do
end program
完成以上步骤后,在命令行中执行fpm run。如果项目能够成功编译并执行,你会在命令行中看到类似于这样的执行结果
Emit an atom with spin down.
Emit an atom with spin up.
Emit an atom with spin up.
Emit an atom with spin down.
Emit an atom with spin up.
在详细解释代码之前,我们先简要介绍这段代码所描述的物理过程。这个小程序模拟的是施特恩-格拉赫实验。
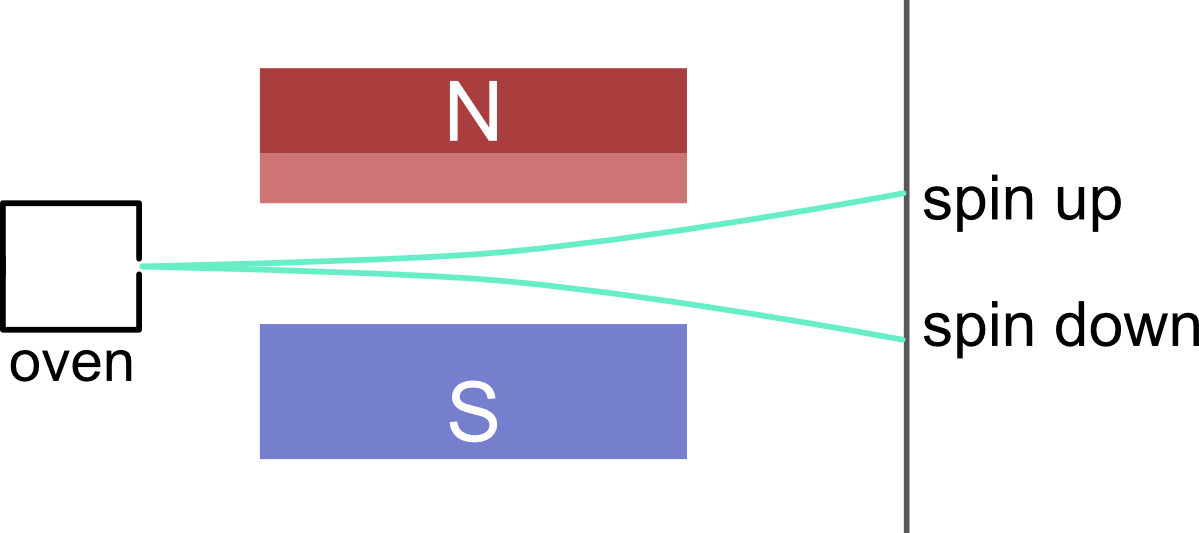 电子具有自旋角动量,可以产生自旋磁矩。由于其自旋角动量的取值是量子化的,且仅有两种取值(我们将其分别标记为spin up和spin down),因而磁矩也仅有两种取向。因此,如果将含有未成对电子的原子束打向非均匀的磁场,其中的原子因磁矩的不同,会偏转产生不同方向的两束原子,在照相板上产生两条分立的沉积痕迹。这个实验使人们第一次观察到电子自旋磁矩的量子化。
电子具有自旋角动量,可以产生自旋磁矩。由于其自旋角动量的取值是量子化的,且仅有两种取值(我们将其分别标记为spin up和spin down),因而磁矩也仅有两种取向。因此,如果将含有未成对电子的原子束打向非均匀的磁场,其中的原子因磁矩的不同,会偏转产生不同方向的两束原子,在照相板上产生两条分立的沉积痕迹。这个实验使人们第一次观察到电子自旋磁矩的量子化。
我们的第一个程序将依次「发射一个原子」,这个原子的自旋角动量是随机的,然后程序将观察结果打印到屏幕中。
模块部分
首先来看Stern_Gerlach_experiment.f90。这个文件中的module Stern_Gerlach_experiment和end module,以及它们包含的内容,构成了一个Fortran模块(module)。模块就像一个工具箱,把关于同一个任务的变量、函数、子程序等都打包在一起,提供给使用这个模块的程序其他部分。Stern_Gerlach_experiment是模块的名字,表明这个模块会提供模拟施特恩-格拉赫实验的功能。
implicit none告诉编译器,在这个模块中的所有变量,都必须显式(explicit)地声明后才能使用。我们建议你在编写程序时,始终使用这个语句,可以有效地避免出现计算结果的错误。
接下来的private语句,会隐藏模块中的定义的所有变量和函数等内容。明明模块是为了提供给他人使用的,为什么还要隐藏其中的内容呢?有两点原因:
- 首先模块中并非所有内容都是应当对外公开的,就像一台仪器,需要用外壳将其机身封装起来,使用者只会操作其外部的按钮。模块中也有一部分是仅供模块内部使用的,将其暴露在外,使用者可能会将其修改,导致错误的结果;
- 其次,一个设计良好的模块,在完成其功能的前提下,应尽可能减少对外提供的内容。这样可以减小使用者的记忆量,更加友好。
然后利用public :: emit_atom语句说明emit_atom这个功能是公开的,使用了这个模块的代码就可以调用emit_atom。
在这个模块中,我们只定义了一个子程序(subroutine)emit_atom。子程序和函数(function)都定义在模块的contains语句之后。与模块的定义非常相似,子程序定义在subroutine emit_atom()和end subroutine之中。subroutine emit_atom()中的括号用于放置虚参列表,不过该子程序并没有虚参,所以这里为空。
real :: raw_number
integer :: spin ! 0代表spin up,1代表spin down
这两行分别定义了一个real类型的变量raw_number和integer类型的变量spin,在该子程序后续内容中,我们可以使用raw_number和spin来储存数值,并用于计算、判断等操作。real类型的变量类似于数学中的实数,可储存包含小数部分的数值,也被称为「浮点数」;integer类型的变量则类似数学中的整数,不包含小数部分。我们定义的spin将可能取值0或1,分别表示spin up状态和spin down状态。
在Fortran中,!用于标记对代码的注释。从!开始一直到行尾的内容都是注释。注释对程序执行不起任何作用,它只是注解代码的功能,方便阅读者理解代码,提高代码的可维护性。我们鼓励读者适当地在代码中添加注释,无论是对于自己还是其他阅读代码的人,都是有好处的。
接下来则是子程序的具体执行部分。
call random_number(raw_number) ! raw_number的范围是[0,1)
spin = nint(raw_number) ! 四舍五入得到0或1
我们首先调用了Fortran内置的子程序random_number,raw_number作为参数接收random_number执行产生的结果。random_number会随机产生均匀落在\([0,1)\)区间的浮点数,因此raw_number的数值就在这个范围里。之后我们调用内置的函数nint根据raw_number的值四舍五入得到整数0或者1,并将该结果赋值给spin。这里的=表示赋值操作,将右边变量的值复制给左边的变量。
对比这两行语句,可以看出子程序与函数调用方式的不同。虽然子程序和函数并没有本质上的不同,但是函数相比子程序多了一个「返回值」。在这个例子中,random_number子程序内部产生随机的值,然后赋值给raw_number,然后我们就可以使用这个值;而nint函数则是根据raw_number的值进行四舍五入,并不会直接修改raw_number,计算得到的整数0或1是通过返回值的方式赋值给spin。当然函数也可以直接修改被传入的参数,我们将在函数与子程序章节讲解。
现在我们随机产生了具有不同自旋状态的原子,我们要观测它们的自旋,并把观测结果输出到屏幕。
if (spin == 0) then ! 判断spin的值,若等于0,则执行下面语句
write (*, *) "Emit an atom with spin up."
else ! 否则执行这一部分
write (*, *) "Emit an atom with spin down."
end if
spin == 0表达式会将spin的值与0进行比较,如果spin的值等于0,得到.true.(logical变量真),反之则得到.false.(logical变量假)。因此,经过比较,如果spin的值为0,就会执行第一个语句,将Emit an atom with spin up.打印到屏幕。
注意,在代码中我们并不是直接写Emit an atom with spin up.,而是用双引号"将其限定。这样得到的是一个字符串,其中的内容为Emit an atom with spin up.。
相应地,如果spin的值为1,就不会执行第一条语句,而是进入到第二条语句,向屏幕输出Emit an atom with spin down.
主函数部分
到此为止,我们已经介绍完Stern_Gerlach_experiment模块的内容,我们现在来看main.f90中的内容。这个源代码文件中定义了program,这是我们程序的「主函数」。主函数是一个可执行Fortran程序必不可少的部分,因为它是程序执行的入口。当执行编译得到的程序时,首先会进入到program中,开始依次执行其中的语句。main是我们为主函数起的名字,你也可以换成其他名字,只要不与程序其他部分的名字冲突。
use Stern_Gerlach_experiment ! 引入模块,从而能够使用其中定义的变量及过程
我们在主函数开头引入此前定义的模块,这样我们就可以在主函数中使用这个模块提供的功能。
同样地,我们在主函数中也使用implicit none语句。注意它与use模块语句的顺序,implicit none必须在所有use语句之后出现。
integer, parameter :: emission_times = 5 ! 实验的观察次数
integer :: i
然后我们为主函数定义必要的变量。i的定义与前面你看到的spin类似,但是你会注意到emission_times有所不同。对于emission_times,除了标记其类型的integer以外,还多了一个parameter。parameter说明了emission_times是一个「常量」,或者说「不可变」的变量,在定义之后就不可再修改其值。显然常量在定义时需要同时指定值,我们将emission_times的值定义为5。
do i = 1, emission_times
call emit_atom()
end do
主函数的主体是一个循环结构。所谓循环,就是重复执行一些语句。我们知道emission_times的值为5,循环开头实际的含义就是do i = 1, 5。这会使i分别被赋值为1, 2, 3, 4, 5,而其中的call emit_atom()语句也会相应执行五次。每次执行emit_atom(),其内部会随机产生一个原子,并打印对原子的观察结果。这样就完成了五次观察实验。
练习
- 尝试更改
emission_times的值,例如将其改为10或者0。重新编译并执行,看看结果有何不同。 - 在执行
call random_number(raw_number)之后打印出raw_number的值,对比其四舍五入后是否与spin的值一致。 - 在
do循环中打印i的值。
变量的定义
本节介绍Fortran中的变量定义,介绍内置的数据类型。
Fortran变量的规则
Fortran中的变量定义分为了两个部分,前者是数据类型,后者是数据的属性,一个变量只能有一个类型,但是可以有多个属性。
基本的数据类型
Fortran中的基本数据类型有5种,每一种还具有不同的kind值,用来表示不同的精度。
| 类型名 | 含义 | kind | 默认kind |
|---|---|---|---|
integer | 整数 | 1,2,4,8 | 4 |
real | 小数 | 4,8,16 | 4 |
complex | 复数 | 4,8,16 | 4 |
character(len=[num]) | 字符串 | 1,4 | 1 |
logical | 逻辑类型 | 1,2,4,8 | 4 |
real类型在编程中通常称为浮点数,而其对应的kind=4,8,16称为单精度,双精度,四精度浮点数。integer类型在编程中称为整型,而其对应的kind=4,8称为整型,长整型。
变量命名规则
Fortran中的可用于变量命名的字符包括数字,下划线,英文字母且不区分大小写。合法的变量名必须以英文字母开始。类型和变量名之间用::分隔,具有相同类型的变量可以写在同一行并用逗号隔开。
给出一个简单的定义变量的例子
program main
implicit none
real::a,sqrt_2
integer::i,number_of_particles
complex::c
character(len=10)::str
logical::flag
end program main
- 此处的
implicit none表示变量未经定义不得使用,在程序中,应当总是使用该语句
这些定义使用的都是默认精度,如果想使用更高的精度,可以在对应的类型后加括号,例如
program main
implicit none
real(8)::a
integer(1)::i
complex(16)::c16
logical(2)::flag
end program main
字面值
Fortran中的字面值拥有的是对应变量类型的默认精度,比如1.0是一个单精度浮点数,如果需要定义更高精度的字面值,在其后加下划线,并标注出kind值,例如
"hello Fortran" ! 字符串
+1.234_8,1.2345e10_8,-1.2345e10_8 ! 双精度浮点数
4294967296_8,-1234_8 ! 长整型
(1.0,2.0) ! 单精度复数
.true.,.false. ! 逻辑值
- 这是Fortran中的一个易错点,因为大部分的编程语言默认的精度都是双精度,所以在切换到Fortran的时候很容易遇到精度不足的问题。
变量赋值
Fortran中的变量赋值使用的是=,使用write输出
!文件名app/main.f90
program main
implicit none
integer::i
real::pi
character(len=8)::str
i=42
pi=3.14159
str="Fortran"
write(*,*)i,pi,str
end program main
运行结果
$ fpm run
Project is up to date
42 3.14159012 Fortran
write(*,*)语句是用来输出的,其中第一个*表示输出位置是屏幕,第二个*表示输出的格式为默认格式。- 与
write相似的read(*,*)表示输入,第一个*表示输入的位置是键盘,第二个*表示输入的格式为默认格式。 - 你可能已经发现输出的浮点数似乎和你设置的值总是不太符合。这和浮点数的精度有关,具体见下一节。
常量属性
在实际的编程中,有些数是不会变的,比如圆周率pi,重力加速度g,这时候就可以将其定义为常量。常量使用parameter来标记,是我们学习到的第一个属性。
!文件名app/main.f90
program main
implicit none
real,parameter::pi=3.1415926
real,parameter::g=9.8
write(*,*)pi,g
end program main
运行结果
$ fpm run
Project is up to date
3.14159250 9.80000019
常量是不可修改的。
同时,我们也可以将变量的kind值定义为常量,用来给字面量设置精度,这样当我们想修改精度的时候,只需要修改常量的值即可
program main
implicit none
integer,parameter::sp=4
real(sp)::a
a=1.234_sp
write(*,*)a
end program main
$ fpm run
Project is up to date
1.23399997
block语句
Fortran2008之前,变量的定义必须在程序的开头完成,Fortran2008引入了block语句,这样我们就可以在程序任意位置定义变量
program main
implicit none
real :: x
block
real :: y ! 局部变量
y = 2.0
x = y ** 2
write(*,*) y
end block
! write(*,*) y !y出了作用域,已经不存在了
write(*,*) x ! 输出 4.00000000
end program main
$ fpm run
Project is up to date
2.00000000
4.00000000
如果你取消注释,则会显示
$ fpm run
[ 66%] Compiling...
app/main.f90:11:16:
11 | write(*,*) y !y出了作用域,已经不存在了
| 1
Error: Symbol 'y' at (1) has no IMPLICIT type
注意事项
- Fortran中的变量只能在程序块的开头定义,执行语句(比如赋值语句)不能出现在变量定义的部分。
- Fortran的赋值可以在变量定义时使用,比如
real::a=123.4,出于一些特别的原因,本教程不使用这种语法。 - 在书写程序的时候,尽量使用有意义的变量名,并搭配合理的注释,使得程序更加清晰明了。
思考题
- 如果变量不定义直接输出,会出现什么问题?
- 如果把一个双精度浮点数的字面值赋值给单精度浮点数变量,会输出什么?
- 对一个带有
parameter属性的量进行修改,会发生什么事情?
变量的表示范围与浮点数精度(提高篇)
本节主要介绍Fortran中的变量的范围,简单介绍IEEE754和浮点数的误差
整数
计算机使用二进制来表示数据,一个默认的整数类型占4个字节,一共有32位,每个位有两种状态,所以一共可以表示的数据量为\(2^{32}\)。
因为我们需要同时表示负数、正数和零,所以,整数的表示范围被设计为\([-2^{31},2^{31}-1]\)一共有\(2^{32}\)个数。
如果需要表示的数据超过了这个限度,那么就需要kind值更大的整数类型integer(8)来表示
浮点数
整数是完全精确的,但是在实际的生活工作中,我们不一定需要这么精确的数,\(\pi=3.14\)或者是\(\pi=3.141592653\)对某些计算来说并不重要。但是相对的,数值可以表达的范围对某些行业更为有用,比如天体之间的距离。所以我们可以舍弃一部分的精确度来换取更大的表示范围,这就是浮点数。
IEEE754
按照IEEE754 浮点数的标准,浮点数由三部分组成:符号位(sign),指针偏移值(exponent)和分数值(fraction)。 一个浮点数是这三部分的乘积\(Value=sign\times exponent \times fraction\)
浮点数的默认类型也是占4个字节,32个位,所以能表示的状态最多也是\(2^{32}\)个,因此,注定有些数字没有办法精确表示,IEEE754的处理方法是:
$$(sign)1+(exponent)8+(fraction)23=32$$
-
用23个位表示一组分数,\(fraction=1+\sum_{i=1}^{23}\frac{a[i]}{2^i}\),其中a[i]表示这个位是0还是1。
-
用8个位表示指数,\(exponent=2^{M-127}\),M的取值范围是[0,255]
浮点数就是利用exponent把给定的fraction按照比例放大或者缩小。即能用这个公式表示出来的都是精确的数,其余的数都是近似等于这些数中的一个。
所以,浮点数的精度是由fraction来决定的,在十进制表示下,精度为\(log_{10}2^{23}=6.923\),所以通常说单精度浮点数的有效数字是6.9
Infinity
当符号位\(M\)取最大值255,且分数位全为0时,此时规定这个值为Infinity
Nan
当符号位\(M\)取最大值255,且分数位不全为0时,此时规定这些值均为Nan
思考题
- 按照浮点数公式,推算在浮点数表示下可以精确表示的最大整数是多少
- 调研什么是非格式化浮点数(denormal)
运算符
本节主要介绍Fortran中的运算符
数(整型,浮点型,复数型)
数的四则运算,幂次
三种数类型有除了有+-*/四则运算之外,还有**幂运算,其规则和数学上的算数运算相似,运算的优先级为**最高,*/次之,+-最低,如果为混合算式,将遵循从左到右的运算顺序。
举例
program main
implicit none
real,parameter::pi=3.14159
real::r,area,circumference
r=2.0
area=pi*r**2 !计算圆的面积
circumference=2*pi*r !计算圆的周长
write(*,*)"area=",area
write(*,*)"circumference=",circumference
end program main
$ fpm run
Project is up to date
area= 12.5663605
circumference= 12.5663605
- 特别的,
**是从右往左的运算顺序,例如2**3**3=2**(3**3)=2**27 - 如果对运算的顺序没有把握,则多加小括号来保证运算顺序
- 整数的除法计算的是商,即
3/2=1而非1.5
数的比较
数的比较运算会返回一个逻辑类型,Fortran支持> < == >= <= /=的比较操作,其中==表示相等,/=表示不相等,一些语言使用!=来表示。
举例
program main
implicit none
write(*,*)1>2,2>=2,3==4,4/=3
write(*,*)2.0>3.0
end program main
$ fpm run
Project is up to date
F T F T
F
- 由于浮点数的精度问题,一般不建议用浮点数进行相等比较。比如判断x是否等于0,
一般采用
abs(x)<eps,其中abs(x)是一个函数,它可以取一个数的绝对值,eps是自己定义的一个变量,用于给定精度。 - 复数不能用来比较
逻辑类型
逻辑类型之间也有自己的运算,分别为与.and. 或 .or. 非 .not. 异或.neqv. 同或 .eqv.,运算之后返回一个逻辑类型。
| 逻辑值A | 逻辑值B | .and. | .or. | .neqv. | .eqv. |
|---|---|---|---|---|---|
.true. | .true. | .true. | .true. | .false. | .true. |
.true. | .false. | .false. | .true. | .true. | .false. |
.false. | .true. | .false. | .true. | .true. | .false. |
.false. | .false. | .false. | .false. | .false. | .true. |
举例
program main
implicit none
real::x
x=1.0
write(*,*) x>0 .and. x<2
write(*,*) x<0 .or. x>1
end program main
$ fpm run
Project is up to date
T
F
- 可以自己加小括号来保证运算顺序
字符串
字符串的拼接
字符串的运算基本运算只有字符串的拼接//
举例
program main
implicit none
write(*,*)"hello "//"world!"
end program main
$ fpm run
Project is up to date
hello world!
字符串还有一些操作是通过内置函数来完成的,我们在函数的章节里再讨论
字符串的比较
字符串也有一系列的比较运算符,按照ascii码来进行比较,特别的
- Fortran字符串中的尾部空格不会计入比较,即
"abc"=="abc ",两者是相等的
一些内置函数
由于Fortran中有一部分内置功能是通过函数来实现的,所以我们在此处先介绍一些用于数值的内部函数。后面的章节中我们会具体介绍函数。
在数值运算中,输入一些值,返回一个值被称为函数。
- 三角函数和反三角函数
- 弧度三角函数 :
sin(x),cos(x),tan(x),asin(x),acos(x),atan(x),atan2(y,x) - 角度三角函数
(Fortran 2023):sind(x),cosd(x),tand(x),asind(x),acosd(x),atand(x),atan2d(y,x)
- 弧度三角函数 :
- 常用数学函数
exp(x),log(x),log10(x),min(x,y,....),max(x,y,....),mod(x,n),其中mod表示关于n取模。 - 特殊函数
- bessel函数 :
bessel_j0(x),bessel_j1(x),bessel_jn(x),bessel_y0(x),bessel_y1(x),bessel_yn(x) - 误差函数:
erf(x),erfc(x),gamma(x),log_gamma(x)
- bessel函数 :
- 转换函数
- 整数转换函数:
int(n),nint(n) - 浮点转换函数:
real(x),aint(n),anint(x) - 复数转换函数:
cmplx(x,y,kind)
- 整数转换函数:
- 字符串函数
- 去除字符串空格:
trim(s) - 字符串长度:
len(s),len_trim(s) - 字符串查找函数:
index(str,sub)
- 去除字符串空格:
更多详细的介绍和示例可以在fortran-lang 内置函数中查看
练习
- 根据三角形的边长
a,b,c,利用海伦公式计算三角形的面积 - 使用内置函数,计算3个数的最大值
- 使用内置函数,计算3个数的中间值
数组
在实际的程序编写过程中,我们有时候需要存储和操作一长串数字,而不是单个标量变量,例如存储100个粒子的位置,50个城市的经纬度。在计算机编程中,此类数据结构称为数组array 。
数组的声明
我们可以声明任意类型的数组,数组的声明需要用到dimension属性,这是我们学到的第二个属性
如果数组的大小在编写程序的时候就是已知的,那么就可以按照如下的方式定义,称为静态数组
program arrays
implicit none
! 一维 integer 数组
integer, dimension(10) :: array1
! dimension的语法糖,和上面的等价
integer :: array2(10)
! 二维数组
real(8), dimension(10, 10) :: array3,array4
! 自定义数组的上标和下标
real :: array5(0:9)
real(8) :: array6(-5:5)
! 也可以使用parameter来定义
integer,parameter::n=10
real(8) :: array7(n)
write(*,*)array7(3) !输出单个数组元素
end program arrays
- Fortran支持数组的最高维度是15维
- Fortran的数组下标从1开始,且定义的时候是左闭右闭,和其他语言不同
- 此类静态数组声明时的大小只能是常数或者具有
parameter属性的常量 - 数组的上下标不能超过定义时的大小,这类错误称为数组越界,在科学计算中十分常见。
数组的列优先
Fortran中数组是按照列优先的方式存储的,即左边的指标更接近
integer::a(2,2)
排列的顺序为a(1,1),a(2,1),a(1,2),a(2,2)
数组初始化与构造器
数组的初始化有多种方式。
首先,Fortran支持将数组整体赋值,例如 a=1的形式就是将数组a中的元素全部赋值为1
其次就是数组构造器,语法是[]
同时数组还支持整体操作,包括运算符+-*/以及**,还有所有的逻辑运算符。对应的就是数组的相应位置做对应的算数操作,因此数组整体操作的时候数组大小和维度必须相同,或者为标量
program arrays
implicit none
integer :: array1(10)
real::array2(3)
array1=1 !整体初始化
array1=[1,2,3,4,5,6,7,8,9,10] !数组构造器
array2=[real::1.0,2.1,3.2] !使用real::语句可以设定数组构造器的类型
array2=array2+[1.0,1.0,2.0]
array2=array2+2.3 !也可以是标量
end program arrays
注意 ,Fortran中数组构造器只能产生一维数组,如果要给多维数组赋值,则需要使用reshape函数,此时依旧是列优先.使用order关键字,可以进行行优先赋值
program arrays
implicit none
integer :: a(2,2),b(2,2)
a=reshape([1,2,3,4],shape=[2,2])
b=reshape([1,2,3,4],shape=[2,2],order=[2,1])
write(*,*)"---------- a ------------"
write(*,*)a(1,1),a(1,2)
write(*,*)a(2,1),a(2,2)
write(*,*)"---------- b ------------"
write(*,*)b(1,1),b(1,2)
write(*,*)b(2,1),b(2,2)
end program arrays
---------- a ------------
1 3
2 4
---------- b ------------
1 2
3 4
数组的切片
数组的切片使用的语法是(start:end[:step]),其中step可以是任意的整数,包括负数。
- 当
step=1时,可以省略 - 当
end表示的是数组末尾的时候,可以省略 - 当
start表示的是数组开头的时候,可以省略
同时数组切片还可以和数组的整体操作运算结合起来,这为Fortran的数组提供了强大的语法糖。
program arrays
implicit none
integer :: array1(10)
array1=[1,2,3,4,5,6,7,8,9,10]
write(*,*)array1(1:10:2) !输出所有的奇数位
array1(6:)=array1(:5)+array1(1:10:2) !利用数组切片加整体运算
write(*,*)array1(10:1:-1) !倒序输出
end program arrays
$ fpm run
1 3 5 7 9
14 11 8 5 2 5 4 3 2 1
同时Fortran还支持使用数组作为数组的下标,此时会产生临时数组
program arrays
implicit none
integer :: array1(10),idx(3)
array1=[10,9,8,7,6,5,4,3,2,1]
idx=[4,6,1]
write(*,*)array1(idx)
end program arrays
$ fpm run
7 5 10
可分配数组(动态数组)
有时候,数组的大小需要在计算中才能得出,前面使用的静态数组由于大小是固定的,有时候并不能满足相应的需求,这时候就需要动态数组。
定义动态数组需要用allocatable属性
program allocatable
implicit none
integer, allocatable :: array1(:) ! 定义一维的可分配数组
integer, allocatable :: array2(:,:)! 定义二维的可分配数组
allocate(array1(10)) !分配大小
allocate(array2(10,10))
! ...
deallocate(array1) !释放
deallocate(array2)
end program allocatable
- 可分配数组的大小可以不确定,但是维数必须确定
- 可分配数组分配之后就可以像普通数组一样使用,但是有一个重分配的机制,即
a=[1,2,3]如果a是一个可分配数组,那么此时a就会重新分配内存,变成一个具有3个元素的数组
Fortran为带有可分配属性的变量提供了一个内置的子程序call move_alloc(from,to),使用这个子程序,可以将from的分配属性转移到to,此时from将被释放
program arrays
implicit none
real,allocatable:: a(:),b(:)
a=[real::1,2,3]
write(*,*)allocated(a),allocated(b) !使用allocated函数检查分配属性
call move_alloc(a,b)
write(*,*)allocated(a),allocated(b)
write(*,*)b
end program arrays
$ fpm run
T F
F T
1.00000000 2.00000000 3.00000000
数组常量
因为常量在定义之后就不能更改了,所以数组常量的定义可以不写具体的大小,只使用(*)代替
program allocatable
implicit none
integer,parameter::a(3)=[1,2,3]
integer,parameter::b(*)=[1,2,3] !使用*代替
integer,parameter::c(0:*)=[4,5,6]!也可以自定义起点
end program allocatable
思考题
- 对二维数组使用数组切片操作,观察其输出
- 对二维数组使用数组作为下标,观察其输出
字符串数组
字符串切片
Fortran中的字符串也支持切片操作,但是相对于数组切片要弱一些,例如,取字符串的第i个字符需要使用str(i:i),不能反向切片,不能间隔切片等
program string
implicit none
character(11)::str
str="hello world"
write(*,*)str(:5)
!write(*,*)str(5),str(1:11:2) ,str(11:1:-1) !以上均不符合语法规范
end program string
$ fpm run
hello
可分配字符串
在Fortran2003引入了可分配的字符串,使用起来更加灵活,可以显式的分配内存,也可以自动分配内存。
使用可分配字符串可以有效的避免字符串拼接之后尾部空格的问题
program allocatable_string
implicit none
character(:), allocatable :: first_name
character(:), allocatable :: last_name
character(:), allocatable :: full_name
! 显式分配内存
allocate(character(4) :: first_name)
first_name = 'John'
! 自动分配内存
last_name = 'Smith'
full_name = first_name//' '//last_name
write(*,*)full_name
end program allocatable_string
$ fpm run
John Smith
字符串数组
在Fortran中,字符串数组中的数组长度必须相同,使用数组构造器时也必须相同
program string_array
implicit none
character(len=10), dimension(2) :: keys
character(len=:) , allocatable :: vals(:) !可分配的字符串数组,定义的时候必须都是可分配的
!character(len=4) , allocatable :: vals(:) !错误
keys = [character(len=10) :: "apple", "tree"] !这样可以给定构造器中字符串的长度
write(*,*)keys(1)(1:3) !字符串数支持这类链式语法
allocate(character(len=4)::vals(4)) !显式分配内存
end program string_array
$ fpm run
app
if条件语句
Fortran中使用条件语句if(<condition>)then来表示某条语句在满足条件时被执行,其中<condition>必须是一个逻辑值。
单分支
当if结构中的语句只有一行时,可是省略then和end if,写为一行
program main
implicit none
integer::angle
angle=10
if (angle < 90) then
write(*,*)"锐角"
end if
!等价形式
if(angle < 90) write(*,*)"锐角"
end program main
$ fpm run
锐角
锐角
- 在 if 结构中缩进代码是一种很好的做法,以使代码更具可读性。
两个分支
当有两个分支时,需要增加else语句或else if语句
program main
implicit none
integer::angle
angle=90
if (angle < 90) then
write(*,*)"锐角"
else
write(*,*)"不是锐角"
end if
!
if (angle < 90) then
write(*,*)"锐角"
else if(angle == 90) then
write(*,*)"直角"
end if
end program main
$ fpm run
不是锐角
直角
- 注意
else if后面还有一个then
多个分支
可以使用多个else if一直连接下去
program main
implicit none
integer::angle
angle=120
if (angle < 90) then
write(*,*)"锐角"
else if(angle == 90) then
write(*,*)"直角"
else if(angle < 180) then
write(*,*)"钝角"
else if(angle == 180) then
write(*,*)"平角"
end if
end program main
$ fpm run
钝角
- Fortran中的if语句并没有短路机制,所以例如
if( i <= 10 .and. a(i) > 1),数组a的大小为10,这样的语法并不能保证在运行时不出错。
program main
implicit none
integer::a(10)
integer::i
i=11
a=2
if (i<=10 .and.a(i)>1)then
write(*,*)"hello"
end if
end program main
$ fpm run
At line 7 of file app/main.f90
Fortran runtime error: Index '11' of dimension 1 of array 'a' above upper bound of 10
select 选择语句
select语句可以对参数进行匹配判断,满足匹配条件的进入对应的case。 其中,只能用于整型,字符串,逻辑型
举例
program main
implicit none
character(len=1)::move
move="a"
select case(move) ! move有wasd四种可能性
case("w");write(*,*)"上" !使用;一行可以写多个语句,可读性更好
case("a");write(*,*)"左"
case("s");write(*,*)"下"
case("d");write(*,*)"右"
case default;write(*,*)"错误的方向" !默认的case,可以省略
end select
end program main
$ fpm run
左
- 练习:尝试修改
move的值,观察输出
同时,case 语句支持指定多个条件进行匹配,也支持范围
program main
implicit none
character(len=1)::c
integer::i,j
i=10
c="W"
j=7
!数字范围
select case(i)
case(1:9) ;write(*,*)"一位数"
case(10:99);write(*,*)"两位数"
end select
!字符范围
select case(c)
case('a':'z') ;write(*,*)"小写字母"
case('A':'Z') ;write(*,*)"大写字母"
end select
select case(j)
case(2,3,5,7) ;write(*,*)"质数"
case default ;write(*,*)"不是质数"
end select
end program main
$ fpm run
两位数
大写字母
质数
- 不支持
1:4:2这类范围
循环
当我们需要一段代码执行很多次的时候,就需要用到循环语句
普通的do循环
Fortran中的循环使用do i=start,end[,step],其中当step为1时,可以省略
program main
implicit none
integer::i
do i=1,4
write(*,*)i
end do
write(*,*)"-------------------"
do i=1,4,2 !循环中1,到4,间隔为2
write(*,*)i !输出奇数
end do
write(*,*)"-------------------"
do i=4,1,-2
write(*,*)i !反向输出偶数
end do
end program main
$ fpm run
1
2
3
4
-------------------
1
3
-------------------
4
2
带条件的循环
如果要求循环在满足某些条件时执行,则需要使用do while语句
program main
implicit none
integer::i
i = 1
do while (i < 11)
write(*,*)i
i = i + 1
end do
! 此处 i = 11
write(*,*)"end:i=",i
end program main
$ fpm run
1
2
3
4
5
6
7
8
9
10
end:i= 11
exit与cycle
遇到cycle语句,后续的语句不再执行,会自动跳到循环的开头
integer::i
do i=1,6
if(i==5) cycle !遇到5,跳过
write(*,*)i !输出1,2,3,4,6
end do
遇到exit语句,后续的语句不再执行,会自动跳出循环
integer::i
do i=1,6
if(i==5) exit !遇到5,退出
write(*,*)i !输出1,2,3,4
end do
- 练习:尝试补全如上程序并运行。
无限循环
显然我们可以使用do while(.true.)构造一个无限循环,Fortran也为我们提供了如下的方式。
integer :: i
i = 1
do
write(*,*)i
i = i + 1
if (i==11) exit !使用 exit 跳出
end do
命名循环
在Fortran中可以为循环命名,exit和cycle语句后可以接循环的名字,这大大提高了代码的灵活性
integer::i
loop1:do i=1,10
loop2:do j=1,10
if(i>5)exit loop1 !满足这个条件跳出循环loop1
write(*,*)i,j
end do loop2
end do loop1
- 使用循环命名可以轻松跳出多层循环
可并行化的循环(do concurrent)
Fortran2008引入,其中的代码可以自动SIMD(目前编译器实现较差,并不能保证并行执行。)
real, parameter :: pi = 3.14159265
integer, parameter :: n = 10
real :: result_sin(n)
integer :: i,j
real :: result_cos(n,n)
do concurrent (i = 1:n) ! 注意语法和do不同使用的是: 而不是,
result_sin(i) = sin(i * pi/4.)
end do
do concurrent (i = 1:n, j=1:n, i>j) ! 支持i,j比较运算
result_cos(i,j) = cos((i+j) * pi/4.)
end do
print *, result_sin
- 支持在语句内定义循环变量
do concurrent(integer::i=1:5)目前gfortran不支持,ifx,ifort,flang支持 - Fortran2018中引入了
reduce,shared等字句,可以进一步增强该语法
隐式循环
隐式循环省略了do,end do,写起来更加方便。在数组构造器中,我们可以使用隐式循环
program main
implicit none
integer::i
integer::a(4)
a=[(i,i=1,4)]
write(*,*)a
end program main
请读者自己尝试运行
program main
implicit none
integer::a(4)
a=[(j,integer::j=1,4)] !也可以内部定义循环变量,目前`gfortran`不支持,`ifx,ifort,flang`支持
write(*,*)a
end program main
$ fpm run --compiler="ifort"
1 2 3 4
在输出的时候也可以使用隐式循环,同时隐式循环还支持嵌套
program main
implicit none
integer::a(4),b(3,3)
integer::i,j
a=[(i,i=1,4)]
write(*,*)(a(i),i=1,4)
b=reshape([( [( i+3*j,i=1,3 )] ,j=1,3 )],[3,3])
write(*,*)((b(i,j),i=1,3),j=1,3)
write(*,*)(i,i+1,i=1,5)
end program main
数组与循环
在前一节中,我们已经看到了隐式循环在数组中的应用,但是在实际的代码编写中,我们需要大量的编写多重循环。隐式循环和数组构造器的组合虽然在直觉上很方便,但是会引入临时数组,带来一定的性能损耗。
数组的列优先
前面我们已经提到了Fortran中的数组是列优先的。所谓列优先就是靠近数组左边的元素,在内存中离得更近。在我们使用多重循环的时候,对离得近的元素优先进行计算,将会带来一定的速度收益, 在计算机科学中,这种被称为访存优化。实际上,想要写出性能较高的Fortran程序,往往只需要注意数组的列优先,以及不要产生过多的临时数组。
一个简单的关于数组列优先优化的例子是矩阵的乘法,一般的矩阵乘法大家都会写成这样
do i=1,n
do j=1,n
do k=1,n
c(i,j)=c(i,j)+a(i,k)*b(k,j)
end do
end do
end do
此时我们看到,内存循环为k,只有b(k,j)满足了列优先的条件,c(i,j)和a(i,k)都是i指标更靠前。所以我们可以尝试如下的优化
do j=1,n
do k=1,n
do i=1,n
c(i,j)=c(i,j)+a(i,k)*b(k,j)
end do
end do
end do
我们可以尝试对比运行时间,来观察速度的变化。这里我们使用了内置的函数system_clock,第一个参数是当前时刻的时间(并不是绝对时间),第二个参数是时间的颗粒度,用两个时刻的时间
相减,再除以颗粒度就是实际的用时(单位为s).
program main
implicit none
integer::i,j,k
integer,parameter::n=1000
real(8)::a(n,n),b(n,n),c(n,n)
integer(8)::tic,toc,rate
call random_number(a) !给数组填充随机数
call random_number(b)
call system_clock(tic,rate)
c=0.0_8
do i=1,n
do j=1,n
do k=1,n
c(i,j)=c(i,j)+a(i,k)*b(k,j)
end do
end do
end do
call system_clock(toc,rate)
write(*,*)"time(ijk)=",1.0_8*(toc-tic)/rate,"s" !注意此处为了避免整数除法,需要这样处理
write(*,*)"c(n,n)=",c(n,n)
call system_clock(tic,rate)
c=0.0_8
do j=1,n
do k=1,n
do i=1,n
c(i,j)=c(i,j)+a(i,k)*b(k,j)
end do
end do
end do
call system_clock(toc,rate)
write(*,*)"time(jki)=",1.0_8*(toc-tic)/rate,"s"
write(*,*)"c(n,n)=",c(n,n)
end program main
我们使用release模式运行,release模式相对于之前的默认模式(通常是debug模式),运行速度更快
$ fpm run --profile release
time(ijk)= 1.3653479070000001 s
c(n,n)= 240.96782832895653
time(jki)= 0.16677901700000000 s
c(n,n)= 240.96782832895653
可以看出,两者的运行时间大概相差了8倍。所以在实际的计算中,我们需要注意数组的列优先带来的收益。
列优先和矩阵的行列
数组的列优先和矩阵的行列没有关系,例如a(1,2)表示的就是矩阵的第一行第二列。所谓列优先只是数组存储和输出的时候按照自己的排布规则,和我们如何理解矩阵无关。
习题
- 写一个选列主元高斯消元法
- (提高)以列优先的规则写一个选列主元的高斯消元法,比较和行高斯消元法的速度
函数
在实际的代码编写过程中,有一些操作是重复的,我们可以将它们提取出来,进行封装,在之后需要使用的时候直接调用。实现这类功能的结构叫做过程(procedure)。
在 Fortran中,具有返回值的过程称为函数(function),不具有返回值的叫做子程序subroutine,在不混淆的情况下,我们可以将其统称为函数。
函数的定义
Fortran中,函数一般定义在module中,置于contains的后面,使用的时候,use这个module就可以导入这个函数。
首先用fpm new my_func_mod创建一个新的项目,然后将module文件放在src/my_func_mod.f90中
! 文件名src/my_func_mod.f90
module my_func_mod
implicit none
contains
function vector_norm(vec) result(norm)
real, intent(in) :: vec(:) !这里vec(:)表示我们传入的是一个数组
real :: norm
norm = sqrt(sum(vec**2))
end function vector_norm
end module my_func_mod
!文件名 app/main.f90
program main
use my_func_mod
implicit none
real::a(3)
a=[real::1.0,2.1,3.2]
write(*,*)vector_norm(a)
end program main
运行之后
$ fpm run
3.95600796
其中result表示函数的返回值是什么,同时我们还需要在函数体中定义返回的类型和属性。
- Fortran中有许多针对数组的内置函数,熟练使用他们,可以减少代码的冗余,提高效率,此处
sum表示对数组进行求和,sqrt表示对元素进行开方
如果返回值没有属性,只有类型,则可以将其写在函数的开头。
将如下的两个文件也放在module中,即vector_norm2的后面
real function vector_norm2(vec) result(norm) !类型写在开头
real, intent(in) :: vec(:)
norm = sqrt(sum(vec**2))
end function vector_norm2
function double_vec(vec) result(vec2)
real, intent(in) :: vec(:)
real :: vec2(size(vec)) !可以返回数组,但是具有dimension属性,不能写在开头
vec2=vec*2
end function double_vec
修改主函数
program main
use my_func_mod
implicit none
real::a(3)
a=[real::1.0,2.1,3.2]
write(*,*)vector_norm(a)
write(*,*)vector_norm2(a)
write(*,*)double_vec(a)
end program main
$ fpm run
3.95600796
3.95600796
2.00000000 4.19999981 6.40000010
size函数返回数组的大小,如果是多维数组,返回的是所有维度的乘积
子过程的参数称为虚参,虚参一般会包含如下几个属性
| 虚参属性 | 说明 |
|---|---|
intent(in) | 参数按照引用传递,拥有只读属性,不可修改 |
intent(out) | 参数按照引用传递,拥有写属性 |
intent(inout) | 参数按照引用传递,拥有读写属性 |
value | 参数按照值传递,内部修改后不影响其原本的值 |
- 在我们使用函数的过程中,尽量要保证函数的参数是
intent(in)或者value的,这类过程也被称为纯函数,这类函数不存在副作用,编译器可以提供更好的优化。 intent(in)也可以和value一起使用,此时值传递的虚参也不可修改。- 如果不能保证纯函数,那可以使用我们下节提到的子程序
- 在代码中应当总是使用
intent属性,这样可以更好的让编译器检查我们的代码
其他位置声明函数
除了在module的contains中定义函数,program,function以及我们接下来要学习的subroutine中都可以使用contains来定义函数,
program main
implicit none
real::a(3)
a=[real::1.0,2.1,3.2]
write(*,*)vec_norm(a)
contains
real function vec_norm(a)result(res)
real,intent(in)::a(:)
res=norm2(a)!内置函数norm2
end function vec_norm
end program main
但是这些位置定义的函数都只在其对应的作用域内有效,出了作用域就无法访问。
子程序
Fortran中不具有返回值的过程称为子程序(subroutine),使用call语句调用这个子程序
子程序的定义和函数类似
!文件名 src/my_sub_mod.f90
module my_sub_mod
implicit none
contains
subroutine print_matrix(A)
implicit none
real, intent(in) :: A(:, :)
integer :: i
do i = 1, size(a,1)
write(*,*)A(i, :)
end do
end subroutine print_matrix
subroutine axpy(alpha,A,B)
! 计算 B=B+alpha*A
implicit none
real, intent(in) :: alpha
real, intent(in) :: A(:, :)
real, intent(inout) :: B(:, :)
B=alpha*A+B
end subroutine axpy
end module my_sub_mod
!文件名 app/main.f90
program main
use my_sub_mod
implicit none
integer,parameter::n=4
real::a(n,n),b(n,n)
integer::i,j
!使用循环赋值
do i=1,n
do j=1,n
a(j,i)=real(i+j)
end do
end do
!调用子程序
call print_matrix(a)
b=1.5
call axpy(2.0,a,b)
write(*,*)"--------------------"
call print_matrix(b)
end program main
$ fpm run
2.00000000 3.00000000 4.00000000 5.00000000
3.00000000 4.00000000 5.00000000 6.00000000
4.00000000 5.00000000 6.00000000 7.00000000
5.00000000 6.00000000 7.00000000 8.00000000
--------------------
5.50000000 7.50000000 9.50000000 11.5000000
7.50000000 9.50000000 11.5000000 13.5000000
9.50000000 11.5000000 13.5000000 15.5000000
11.5000000 13.5000000 15.5000000 17.5000000
- 子程序的参数也具有
intent属性,合理使用intent属性可以使得代码更加稳健 - 子程序中纯过程的定义更加灵活,参数可以是
intent(inout)属性。如果函数不能写成纯的,可以考虑写成子程序
过程的其他特性
过程的附加标识
pure纯过程
在函数或子程序的开头添加pure关键字,可以要求该过程是纯的,即其中没有副作用
pure real function vector_norm(vec) result(norm)
implicit none
real, intent(in) :: vec(:)
norm = sqrt(sum(vec**2))
end function vector_norm
elemental逐元过程
逐元过程在定义的时候虚参只能是标量,但是在调用的过程中可以直接用于任意维数组。
module my_func_mod
implicit none
contains
elemental integer function gcd(m,n)result(res)
integer,value::m,n
do while(n>0)
res=mod(m,n)
m=n
n=res
end do
res=m
end function gcd
end module my_func_mod
program main
use my_func_mod
implicit none
write(*,*)gcd(10,5)
write(*,*)gcd([10,20],4) !参数可以是数组和标量
write(*,*)gcd([10,20],[4,8]) !参数可以都是数组
end program main
$ fpm run
5
2 4
2 4
impure非纯过程
逐元过程默认是pure的,但是你可以使用impure关键字将其定义为非纯过程
module my_sub_mod
contains
impure elemental subroutine print_vec(a)result(res)
real,intent(in)::a
write(*,*)a !带有输出,不是一个纯的过程
end subroutine print_vec
end module my_sub_mod
program main
use my_sub_mod
implicit none
call print(1.0)
call print([1.0,1.1])
end program main
recursive递归过程
过程默认不具有递归属性,添加recursive关键字后,可以递归调用
! 斐波那契数列
recursive integer function fib(n)result(res)
integer,value::n
if(n==1)then
res=1
return
elseif(n==2)then
res=2
return
else
res=fib(n-1)+fib(n-2)
end if
end function fib
- 此处我们使用了
return语句,注意Fortran中的return语句并不返回任何东西,所做的就是直接跳到子程序(函数)的末尾,然后退出。
关键字参数
Fortran中的子过程,它的参数可以通过关键字参数给定,即使用虚参名=实参的形式
可选参数
具有可选参数的虚参需要添加optional属性,使用 present内置函数检查参数是否存在
module my_func_mod
implicit none
contains
real function area(x,y)result(res)
real,intent(in)::x
real,intent(in),optional::y
if(present(y))then
res= x * y
else
res = x * x
end if
end function area
end module my_func_mod
program main
use my_func_mod
implicit none
write(*,*)area(4.0) !正方形面积
write(*,*)area(4.0,5.0) !长方形面积
write(*,*)area(y=4.0,x=5.0) !可以使用关键字参数
end program main
$ fpm run
16.0000000
20.0000000
20.0000000
回调函数
将函数作为参数传递给函数,这个功能称为回调函数,例如我们写一个数值积分,我们希望传入积分的上下界,以及一个一元函数。此时我们需要限制虚参的接口,防止别人传入一个多元函数。Fortran提供了抽象接口(abstract interface)来实现这个功能,使用procedure关键字来定义虚参
同样的,抽象接口也放在module中
module trapz_mod
implicit none
abstract interface
real function func_1d(x)result(res)
real,intent(in)::x
end function func_1d
end interface
contains
real function trapz(a,b,f) result(res)
real,intent(in)::a,b
procedure(func_1d)::f
res=(f(a)+f(b))/2
end function trapz
real function mysin(x)result(res)
real,intent(in)::x
res=sin(x)
end function mysin
real function mycos(x)result(res)
real,intent(in)::x
res=cos(x)
end function mycos
end module trapz_mod
program main
use trapz_mod
implicit none
write(*,*)trapz(1.0,2.0,mysin)
write(*,*)trapz(1.0,2.0,mycos)
end program main
$ fpm run
0.875384212
6.20777160E-02
习题
- 完成
trapz数值积分,求解sin(x)+cos(x)在[0,1]上的积分 - 完成用于求解微分方程的Runge-Kutta方法
rk4计算 $$y'=\frac{(e^{-x}-y)}{2},y(0)=0.5$$ 严格解为 $$y=e^{-x}(1.5e^{\frac{x}{2}}-1)$$
模块的其他特性
我们也可以将变量存放在模块中。注意,模块中存放的都是定义,不能有执行语句。借助模块,我们可以对变量和过程进行封装,提高代码的可读性,一致性,可移植性。
模块中的变量和过程有三种属性private(私有),public(公有),protected(保护,模块内可以修改,模块外只能访问不能修改),默认的属性是public
变量属性
module my_mod
implicit none
private !第一种定义方式全局其效果
public::public_var, print_matrix !第二种定义方式,只对限定的起效果
real, parameter :: public_var = 2
integer :: private_var
integer,protected:: cnt=0 !第三种直接在声明时添加
contains
subroutine print_matrix(A)
real, intent(in) :: A(:,:) !另一种数组传递的方式,可以省略一些虚参,并提供接口检查,推荐使用
integer :: i
cnt=cnt+1 !统计函数调用次数
do i = 1, size(A,1)
print *, A(i,:)
end do
end subroutine print_matrix
end module my_mod
其他的导入形式
program use_mod
use my_mod !使用这个模块
implicit none
real :: mat(10, 10)
mat(:,:) = public_var
call print_matrix(mat)
end program use_mod
同时还可以显式导入
use my_mod, only: public_var
为了防止命名冲突,还可以使用别名导入
use my_mod, only: printMat=>print_matrix
多文件
可以将不同的module保存到不同的文件中,这样在使用的时候可以编译对应的模块,也可以提高移植性。可以提前编写一些通用的模块,提高代码的复用程度。
例如,我们可以定义一个parameter_mod模块,用于封装一些常量,方便后续使用
module parameter_mod
implicit none
integer,parameter :: wp = 8
real(wp),parameter :: pi = acos(-1.0_wp)
real(wp),parameter :: e = exp(1.0_wp)
complex(wp),parameter :: imag1 = (0.0_wp, 1.0_wp)
real(wp),parameter :: hbar = 6.62607015e-34_wp
end module parameter_mod
- 现代的Fortran程序应当是一个主程序和多个
module组成
内置模块
语法标准目前支持五个内置的模块
iso_fortran_env中提供了一些常量的定义,包括数值的精度,输入输出错误流,等等iso_c_binding中定义了用于和c语言交互的一些函数,定义等等ieee_exceptions, ieee_arithmetic, ieee_features支持了ieee异常和算数
过程和运算符重载
在实际的函数编写过程中,有时候需要涉及多重类型,不同维度的数组。我们通常希望提供更加简单一致的接口,方便调用,这时候就需要用到重载。
过程重载
使用interface就可以对相关的过程进行重载
Fortran 2018引入了generic关键字,也可以对函数进行重载,语法大大简化(gfortran不支持,ifx,flang支持)
! src/add_mod.f90
module add_mod
implicit none
interface add
module procedure add_int
module procedure add_real
end interface
! Fortran 2018 与上面四句等价
!generic::add=>add_int,add_real
contains
elemental integer function add_int(a,b)result(c)
integer,intent(in)::a,b
c=a+b
end function add_int
elemental real function add_real(a,b)result(c)
real,intent(in)::a,b
c=a+b
end function add_real
end module add_mod
! app/main.f90
program main
use add_mod
write(*,*)add(1,2)
write(*,*)add(1.0,2.0)
!write(*,*)add(1.0,2) !错误 报错的一般形式为 no specific function for the generic 'add'
end program main
$ fpm run
3
3.00000000
如果使用generic语法,则使用fpm run --compiler ifort
运算符重载
对内置的运算符进行重载,有时候可以提高代码的一致性。
module add_mod
implicit none
interface operator(+)
module procedure add_str
end interface
! Fortran 2018 与上面等价
!generic::operator(+)=>add_str
contains
function add_str(a,b)result(c)
character(len=*),intent(in)::a
character(len=*),intent(in)::b
character(len=:),allocatable::c
c=trim(a)//","//trim(b)
end function add_str
end module add_mod
program main
use add_mod
write(*,*)'"',"hello "+"world ",'"'
end program main
$ fpm run
"hello,world"
- 运算符重载有时候会写出比较含糊的代码,建议要谨慎使用。
- 不可以对运算符二次重载,例如我们无法对整数的加法再进行重载
自定义运算符
除了内置的运算符之外,Fortran也支持自定义运算符,使用两个点.作为标记,例如我们之前接触的.lt.,.ge.等
module find_mod
implicit none
interface operator(.in.)
module procedure find
end interface
! Fortran 2018 与上面等价
!generic::operator(.in.)=>find
contains
logical function find(v,a)result(res)
integer,intent(in)::v
integer,intent(in)::a(:)
integer::i
res=.false.
do i=1,size(a)
if(a(i)==v)then
res=.true.
return
end if
end do
end function find
end module find_mod
program main
use find_mod
write(*,*) 1 .in. [1,2,3,4]
write(*,*) 5 .in. [1,2,3,4]
end program main
$ fpm run
T
F
- 重载的函数和运算符不能用于Fortran的回调函数中。Fortran目前也没有
lambda表达式。
内置函数
Fortran中提供了大量的内置函数,熟练使用这些内置函数,可以有效提高写代码的效率。
所有的内置函数均可以在
大部分用于数和数组类型的函数都是逐元函数,可以同时接收标量和数组。
一些易错点
内置函数中有一些易错点,有一些属于设计缺陷。
-
cmplx(a [,b] [,kind])函数,cmplx函数用于构造一个复数,但是在实际的计算中,cmplx(1.0_8,1.0_8)的返回值并不是一个complex(8)的类型,而是一个complex(4)的类型,cmplx(1.0_8,1.0_8,8)这样才能返回合适的类型。 -
minloc(array [,dim] [,mask]),maxloc(array [,dim] [,mask]),这两个函数用于返回数组中最小值,最大值的位置。当你传入的是一个一维数组的时候, 它实际的返回值式integer::idx(1)类型,是一个数组而不是一个数。minloc(array,dim=1)这样写可以返回一个数。 -
dot_product(a,b)这个函数用于计算两个一维数组的内积,需要注意的是,当传入的是complex类型的时候,它实际上计算的是\(a^{H}b\)而不是\(a^{T}b\) -
reshape,mamtul这些返回数组的内置函数,在ifort/ifx中优化很差,会造成栈溢出stack overflow,需要谨慎使用。 -
reduce,reduce接收一个数组,并对数组元素做相对应的规约操作(目前仅ifx/ifort支持)规约操作是指对于矩阵
a和运算f(x,y),假设有初始值iddo i=1,n id = f(id,a(i)) end do例如计算一个数组的模
program main implicit none write(*,*)reduce([real::1,2,3],add_pow) contains pure real function add_pow(x,y)result(f) real,intent(in)::x,y f=sqrt(x**2+y**2) end function add_pow end program main- 练习:查询相关函数的文档,思考如何计算一个数组的模平方
- 练习:使用reduce计算数组的最大公约数,最小公倍数
文件读写
文件打开关闭
Fortran使用open语句打开文件,其中有两个必填的参数,一个为unit,表示文件的通道号,作为文件的唯一标识,另一个为file表示文件名。最后使用close关闭文件。
open(unit=10,file="1.txt")!unit关键字可以省略
close(10)
- 文件通道号一般设置大于10的数
- Fortran2003提供了一个新的参数,称为
newunit,可以让编译器帮你自动设置文件通道号,不过带来的不便之处就是你可能需要在子程序中引入这个虚参。
integer::myunit
open(newunit=myunit,file="1.txt")!newunit不能省略
close(myunit)
如果要设置文件具有只读权限,必须使用指定关键字 status 和 action
integer :: io
open(newunit=io, file="log.txt", status="old", action="read")
close(io)
如果要打开一个二进制文件,则需要使用form 和access关键字
integer :: io
open(newunit=io, file="log.bin", form="unformatted",access="stream")
close(io)
- 二进制文件中,元素是按照其二进制表示逐个保存的,没有分隔符
文件读写
使用read来读入文件,第一个参数是文件的通道号,第二个参数是文件的格式
integer :: io
open(newunit=io, file="log.txt", status="old", action="read")
read(io,*)a,b
close(io)
read语句有一个很有用的选项是iostat,它表示当前的读取是否正常,当其等于0时表示读取正常,否则表示读取不正常。我们可以使用这个选项来判断读取是否错误,或者是否遇到了文件末尾。
integer :: io,ios,n
character:: line
open(newunit=io, file="log.txt", status="old", action="read")
n=0
do
read(io,*,iostat=ios)line
if(ios/=0)exit !读取不正常,跳出循环
n=n+1
end do
close(io)
write(*,*)"linenum",n
例如通过这样读取文件,就可以判断一个文件的行数。
- 上述方法在文件中有空行的时候就失效了,如果要计算空行的话,则需要下一节的格式化读取。
使用write来写入文件,第一个参数是文件的通道号,第二个参数是文件的格式
integer :: io
open(newunit=io, file="log.txt")
write(io,*)a,b
close(io)
当你读写的文件是二进制文件的时候,就不需要填写格式参数
integer :: a(100,100) !a是一个数组
open(10, file="r.bin", form="unformatted",access="stream")
open(11, file="w.bin", form="unformatted",access="stream")
read(10) a
write(11) a+100
close(10)
close(11)
- 二进制文件的读写速度很快
格式化输出
使用格式化使得读取和写入的数据更加美观,Fortran的格式描述符使用"()"包围
常用格式描述符
| 格式类型 | 格式符 | 说明 |
|---|---|---|
| 整数 | i | 需要加宽度,例如i10,表示宽度是10 |
| 浮点数 | f | 需要加宽度和小数点后位数,例如f10.5,表示宽度是10,小数点后5位 |
| 科学计数法 | es | 需要加宽度、小数点后位数和科学计数的指数,例如es24.15e3,表示宽度是24,小数点后15位,指数3位 |
| 字符 | A | 可以加宽度,例如a3,标识宽度是3 |
| 通用格式 | g0 | 输出时使用,适用于任意类型 |
| 空格 | x | 输出一个空格 |
Fortran支持在每个描述符的前面添加次数标记,例如10i3,20(f10.5,i10),这样就可以多层嵌套,组合出更多的格式。
同时可以使用*作为标记次数,此时表示的是能输出的最大次数
write(*,"(i3)")123
write(*,"(3f10.4)")[1.0,2.0,3.0]
write(*,"(*(g0,1x)"))1.0,"hello",2
"(*(g0,1x)")和Fortran的默认输出*看起来似乎是相同的功能。事实上不同的编译器对于*的实现各不相同,例如gfortran的输出中有大量的空格,ifort,ifx在80个字符后会自动换行,使用这个格式就可以保证用最小的宽度输出。
如果格式的次数比后面需要输出的参数要少,那此时会自动换行
real::a(3,3)
write(*,"(3f10.4)")a !此时输出的是一个3*3的矩阵形式
在默认格式*中,每个read会至少读取一行,所以一个空的read可以跳过当前行,一个非空的read可以跳过连续的空行,而read后如果是一个数组或者多个元素,则它会一直向后读取直到所有元素全部读取。
!读取一个数组
real::a(10,10)
read(10,*)a !文件中至少需要100个real型数字
- 建议在
read的过程中尽量不要使用格式,因为它要求你的格式和你的文件内容完全符合,这样丧失了一定的灵活性。直接使用表控格式读取更加灵活。 - 在读取字符串的时候,默认会按照分隔符分割,此时使用格式
A就可以读取一行中所有的字符read(10,"(A)"),使用"(A)"格式就可以解决我们上一节提到的空行的问题。
内部文件读写(数字和字符串互转)
write(*,*)和read(*,*)的第一个位置也可以填写字符串,用于数字和字符串的相互转换
character(len=10)::str
real::a
write(str,"(f10.2)")1.234
read(str,*)a
- 注意到Fortran的文件名是一个字符串,所以可以用内部文件读写来批量的生成文件名
派生类型(自定义类型)
当我们需要将一些基础类型组合起来使用,例如定义一个粒子,考虑它的质量,速度,位置等各种信息,如果单独声明变量则代码会显得冗余,此时就可以使用自定义类型
类型的定义
Fortran中使用type关键字来定义派生类型 (其他语言中叫做结构体或者类)
type :: particle_t
real :: mass , v (3) ,x(3) !质量,速度,位置
end type particle_t
派生类型同时还可以作为其他派生类型的成员,我们可以将其自由组合,构造出适合我们当前问题的类型。
type :: electron_t
type(particle_t)::p
integer :: charge !添加电荷属性
end type electron_t
- 自定义的类型一般定义在
module中 - 包含的元素我们称为成员
同时,一个类型也可以由另一个类型扩展而来
type, extends(particle_t) :: electron_t
real :: spin !添加自旋属性
end type electron_t
此时结构体electron_t中包含了成员mass,v,x,也包含了 spin
派生类型成员的访问和初始化
使用%可以对成员进行访问。每个派生类型都有一个内置的构造函数,可以直接进行初始化
module particle_mod
implicit none
type :: particle_t
real :: mass , v (3) ,x(3)
end type particle_t
end module particle_mod
program main
use particle_mod
implicit none
type(particle_t)::p
type(particle_t)::parray(100)!也可以定义为数组
type(particle_t),allocatable::palloc(:)!也可以定义为可分配数组
p%mass=1.0 !使用%进行访问并初始化
p=particle_t(1.0,[1.0,-2.0,3.0],[1.0,1.0,2.0]) !使用构造函数初始化
p=particle_t(v=[1.0,-2.0,3.0],x=[1.0,1.0,2.0],mass=1.0) !也可以使用关键字参数
end program main
自定义类型的输出
如果类型中的成员不带有特殊属性,则可以直接使用write输出,否则旧无法直接使用write输出,此时可以使用%对指定的成员输出
module test_mod
implicit none
type :: point
real :: x,y
end type point
type :: string
character(len=:),allocatable::str !allocatable为特殊属性
end type string
end module test_mod
program main
use test_mod
implicit none
type(point)::p
type(string)::s
p=point(1.0,2.0)
s=string("hello")
write(*,*)p
!write(*,*)s !错误
write(*,*)s%str !正确
end program main
过程绑定
Fortran2003开始支持过程绑定,将子程序或者函数与对应的类型相关联,使用的方法和访问成员类似。这样的做法可以提高代码的一致性。
过程绑定的语法
过程绑定中, 对应子过程的虚参声明需要使用class关键字。同时在类型的定义中使用procedure关键字将其绑定,使用contains将类型和函数分开。
析构函数
程序运行结束之后,这个对象需要释放,此时使用final关键字可以指定一个函数为析构函数。当释放的时候就会调用这个函数。
module vector_mod
implicit none
type vector_t
real,allocatable::x(:)
integer::capacity
integer::size
contains
procedure,pass:: init => vector_init
procedure,pass:: append => vector_append
final :: vector_final
end type vector_t
contains
subroutine vector_init(this,n)
class(vector_t),intent(inout)::this
integer,intent(in)::n
allocate(this%x(n))
this%size=0
this%capacity=n
end subroutine vector_init
subroutine vector_append(this,val)
class(vector_t),intent(inout)::this
real,intent(in)::val
this%size=this%size+1
this%x(this%size)=val
end subroutine vector_append
subroutine vector_final(this)
type(vector_t),intent(inout):: this !此处是type 不是class
if(allocated(this%x))deallocate(this%x) !释放可分配数组
this%size=0
this%capacity=0
write(*,*)"call final"
end subroutine vector_final
end module vector_mod
program main
use vector_mod
implicit none
block
type(vector_t)::v
call v%init(10)
call v%append(1.0)
call v%append(2.0)
write(*,*)v%x(1:v%size)
end block !离开作用域时会调用析构函数
write(*,*)"done"
end program main
pass关键字用来指定在调用的过程中,被调用的类型会自动传递为第一个虚参,与之对应的还有nopass,不自动传递pass(this)关键字也可以带具体的参数,用于指定哪个虚参被自动传递。当你的函数中有多个虚参都是当前类型的时候,你可以指定任意一个。- 使用
=>可以为绑定的过程重命名。 - 被绑定的变量名尽量使用
this或者self(与其他语言的习惯相符)
习题
- vector的
append函数并没有考虑超过capacity的情况。重写这个函数,使其可以在元素超出的时候自动扩容。 - (附加题)使用
move_alloc子程序完成上述功能。 - 使用我们之前提到的函数重载功能重载
size函数,使得size(v)返回v%size - 使用
size(v)返回v%size会带来什么问题,提示(定义vector_t类型的数组)
自定义类型的重载
函数重载
当定义的函数很多的时候,函数名会非常复杂,有时候我们希望可以简化,这时候,使用重载是一个选择。例如对于vector类型,我们希望它也可以通过传入一个数组来初始化。使用generic关键字就可以对函数进行重载
module vector_mod
implicit none
type vector_t
real,allocatable::x(:)
contains
generic::init=>vector_init,vector_init_array
procedure,pass:: vector_init,vector_init_array
end type vector_t
contains
subroutine vector_init(this,n)
class(vector_t),intent(inout)::this
integer,intent(in)::n
allocate(this%x(n))
end subroutine vector_init
subroutine vector_init_array(this,a)
class(vector_t),intent(inout)::this
real,intent(in)::a(:)
allocate(this%x,source=a)
end subroutine vector_init_array
end module vector_mod
program main
use vector_mod
implicit none
type(vector_t)::v
type(vector_t)::va
call v%init(10)
call va%init([real::1,2,3,4])
end program main
此时使用两种方式均可以对其进行初始化。
运算符重载
有时候,我们也希望对内置的运算符进行重载,用来提高代码的一致性。例如我们有一个分数类型,它有+-*/和**的操作,但是如果使用过程绑定的函数则显得代码过于臃肿。此时就可以使用运算符重载
module frac_mod
implicit none
type frac
integer(8)::num!numerator
integer(8)::den!denominator
contains
generic::operator(.reduce.)=>cancelling !也可以使用自定义运算符
generic::operator(+)=>add,add_frac_num,add_num_frac
!generic::operator(-)=>sub
!generic::operator(*)=>mult
!generic::operator(/)=>div
!generic::operator(**)=>pow
!
procedure,pass ::add,add_frac_num
procedure,pass(this)::add_num_frac
procedure,pass ::cancelling
!procedure,pass::sub
!procedure,pass::mult
!procedure,pass::divi
end type
contains
elemental function cancelling(this)result(z)
class(frac),intent(in)::this
type(frac) ::z
! do something
end function cancelling
type(frac) elemental function add(this,y)result(z)
class(frac),intent(in)::this,y
z%num=this%num*y%den+y%num*this%den
z%den=this%den*y%den
end function add
type(frac) elemental function add_frac_num(this,m)result(z)
class(frac),intent(in)::this
integer,intent(in) ::m
z%num=this%num+this%den * m
z%den=this%den
end function add_frac_num
type(frac) elemental function add_num_frac(m,this)result(z)
class(frac),intent(in)::this
integer,intent(in) ::m
z%num=this%num+this%den * m
z%den=this%den
end function add_num_frac
end module frac_mod
program main
use frac_mod
implicit none
type(frac)::x,y,z,w(2)
x=frac(1,2)
y=frac(2,3)
w=[frac(1,4),frac(1,3)] !自定义类型数组初始化
z=x+y
write(*,*)z
z=x+1
write(*,*)z
z=2+y
write(*,*)z
write(*,*)w+2 !也支持数组
end program main
- 除此之外,也可以对比较运算符进行重载,注意比较运算符中运算符和其对应的旧形式属于同一个函数,不能重载为不同的功能。
赋值运算符的重载
赋值的运算符具有特有的形式assignment(=)
module string_mod
implicit none
type string
character(:),allocatable::str
contains
generic::assignment(=)=>equal
procedure,pass::equal
end type string
contains
subroutine equal(this,s)
class(string),intent(inout)::this
character(len=*),intent(in)::s
this%str=s
end subroutine equal
end module string_mod
program main
use string_mod
implicit none
type(string)::s
s="123"
!内置构造函数形式
s=string("456")
end program main
习题
- 请你尝试补充完所有的运算符
- 尝试加入
gcd对分数进行约分,补充.reduce.函数 - (附加题)完成分数类,并使用高斯消元法求解希尔伯特矩阵的行列式和逆矩阵
指针
当我们需要创建一些动态数据类型的时候,例如链表,二叉树,这时候就需要指针。
指向变量的指针
使用pointer关键字可以创建一个指针,使用=>可以指向对应的目标,此时要求被指的对象具有target属性,或者pointer属性
integer,target::x
integer,pointer::px=>null() !提供了null()指针将其指向空
px=>x
x=3
write(*,*)x,px
px=5
write(*,*)x,px
Fortran中的指针并不是获取地址,而是获取目标的引用。你可以理解成px是x的一个别名,当我们修改px和x带来的效果是一样的。
- Fortran中之所以要求被指针指向的变量具有
target或者pointer属性是为了防止在优化过程中这个变量被优化掉
指向数组的指针
指向数组的指针需要给定维度,但是不能指定大小,只能用:表示。
integer,target::x(10)
integer,pointer::px(:) !只能定义为(:)
px=>x
x=3
write(*,*)px
px=>x(1:10:2) !可以指向数组切片
write(*,*)px
!px=>x([1,2,3])!错误,不能指向数组下标,因为数组下标返回的是临时数组
从这里可以看出Fortran中的数组在定义的时候是连续的,但是在使用的过程中不一定是连续的。
指针分配内存
我们也可以为指针分配内存,它和可分配数组的使用类似
integer,pointer::p
integer,pointer::pa(:,:)
allocate(p) !分配一个标量
allocate(pa(10,10))!分配一个数组
deallocate(p) !释放
deallocate(pa)
- 需要注意的是,在使用函数的时候,作为局部变量,可分配变量离开了作用域会自动释放,但是指针不会
使用associated可以查看指针的关联属性
integer,pointer::pa(:)
integer,allocatable,target::a(:)
allocate(a(3),source=[1,2,3])
pa=>a
write(*,*)associated(pa) !检查pa是否被关联
write(*,*)associated(pa,a)!检查pa是否和a关联
内存泄漏
如果对指针进行了分配,但是同时有用它指向了其他的内存,那么就会出现内存泄漏。
integer,pointer::pa(:)
integer,target::a(3)
allocate(pa(3))
pa=[1,2,3]
a=[4,5,6]
pa=>a !内存泄漏
write(*,*)pa
write(*,*)a
- 为
pa分配的内存没有其他的指针指向它,所以我们再无法访问到,但是它同时又没有被释放
指针悬垂
而另一种情况就是指针指向的内存被释放了,但是我们还是继续使用该指针,这种情况称为指针悬垂。
integer,pointer::pa(:)
integer,allocatable,target::a(:)
allocate(a(3),source=[1,2,3])
pa=>a
write(*,*)pa
deallocate(a)!pa现在指向了一块被释放的内存
write(*,*)pa
所以,在对应的操作之后,我们需要同时将指针置空,有两种语法。
! 1.
nullify(pa)
! 2.
pa=>null()
例如具有allocatable属性的局部变量,出了作用域会被自动释放,如果用指针指向它,也会造成指针悬垂
关联(associate)
Fortran2003中引入了associate语句,可以简化在代码编写过程中的临时变量问题,基本的语法是
integer::point(3)
integer::l
point=[1,2,3]
associate(x=>point(1),y=>point(2),z=>point(3))
l=x**2+y**2+z**2
end associate
需要注意的是,此时,如果x=>p的右边是变量,那么x相当于是p的别名,修改了x,p也会随之改变。如果右边是表达式,那么相当于自动创建一个临时变量。此时其中的变量不需要额外的声明
integer::a(10)
integer::i
a=[(i,i=1,10)]
associate(odd=>a(1:10:2),x=>2*2) !前者为引用,后者为直接创建的临时变量
odd=odd+x
end associate
write(*,*)a
- 当我们具有一些比较层数比较深的自定义类型的时候,在代码中使用
associate会大大提高代码的可读性
associate(px=>this%particle%x,py=>this%particle%y)
dis=px**2+py**2
end associate
- 同一个语句中不能连续定义
associate(x=>point(1),x2=>x*x ) !错误
end associate
需要改成
associate(x=>point(1))
associate(x2=>x*x)
end associate
end associate
这是associate结构的不足之处
内存安全
现代Fortran在不引入指针的情况下,是一个内存安全的语言(但是Fortran编译器可能不安全),但是还有一个简单的情况是无法处理的,即变量的别名。
在Fortran中,对于处于同一个作用域内的变量,一般不存在别名(不引入指针的情况下),但是Fortran的标准中规定子程序的虚参是不含别名的,但是在实际的代码编写过程中不一定能保证这件事。
一个典型的内存别名的例子是
module test_mod
implicit none
contains
subroutine test(a,b)
integer,intent(in)::a
integer,intent(inout)::b
b=a+b
b=b+b
end subroutine test
end module test_mod
program main
use test_mod
implicit none
integer::a,b
a=2
call test(a,a)
write(*,*)a
a=2
b=0
call test(a,b)
write(*,*)b
end program main
此时,第一个例子test中传入的参数均为a,那么在test中a即使intent(in)属性又是intent(inout)属性。而在test的作用域中,变量a和b实际上表示的是同一块内存。这为我们实际的代码调试检查
带来了一定的难度,所以在实际的代码编写中,尽量要杜绝这类代码。
同时,在使用我们前一节提到的associate的时候,要注意同时操作两个别名对数据进行处理的情况。
过程指针
指针也可以指向过程,这时候需要先声明指针的接口,用于限制指针的类型,也就是在之前的章节中我们提到的abstract interface
module proc_pointer_mod
implicit none
abstract interface
real(8) function func1d(x) result(res)
real(8),intent(in)::x
end function func1d
end interface
contains
real(8) function mysin(x) result(res)
real(8),intent(in)::x
res=sin(x)
end function mysin
real(8) function myexp(x) result(res)
real(8),intent(in)::x
res=exp(x)
end function myexp
real(8) function mycos(x) result(res)
real(8),intent(in)::x
res=cos(x)
end function mycos
end module proc_pointer_mod
program main
use proc_pointer_mod
implicit none
procedure(func1d),pointer::ptr=>null()
ptr=>mysin
write(*,*)ptr(1.0_8)
ptr=>myexp
write(*,*)ptr(1.0_8)
ptr=>mycos
write(*,*)ptr(1.0_8)
end program main
- 不能使用过程指针指向通用函数名。由于Fortran的内置函数都是经过重载的通用函数,所以也不能用过程指针指向内置函数
如果定义一个过程指针数组,则需要使用到自定义类型,同时也要指定nopass关键字,用来表示不需要绑定该类型作为第一个虚参传递。
module proc_pointer_mod
implicit none
abstract interface
real(8) function func1d(x) result(res)
real(8),intent(in)::x
end function func1d
end interface
type ptrfunc
procedure(func1d),pointer,nopass::ptr
end type ptrfunc
contains
real(8) function mysin(x) result(res)
real(8),intent(in)::x
res=sin(x)
end function mysin
real(8) function myexp(x) result(res)
real(8),intent(in)::x
res=exp(x)
end function myexp
real(8) function mycos(x) result(res)
real(8),intent(in)::x
res=cos(x)
end function mycos
end module proc_pointer_mod
program main
use proc_pointer_mod
implicit none
type(ptrfunc)::a(3)
integer::i
a(1)%ptr=>mysin
a(2)%ptr=>myexp
a(3)%ptr=>mycos
write(*,*)(a(i)%ptr(1.0_8),i=1,3) !此处使用隐式循环输出
end program main
- 使用过程指针后,一些操作需要转向运行时确定,所以编译器无法进行更加激进的优化(内联inline),代码的运行速度有可能会降低。
习题
- 思考为什么不使用
procedure(func1d),pointer::ptr(:)来定义过程指针数组
指针的小技巧
数组的维数变换
Fortran中的数组在定义了维数之后,一般是不可变的。这是我们可以使用指针来为其设置一个别名
integer,target::a(4,4)
integer,pointer::pa(:)
pa(1:size(a))=>a !此时需要设置指针的宽度,且右边只能是一维或者连续的数组
这时候我们就获得了一个a的一维数组别名
integer::i
pa=[(i,i=1,16)]
write(*,*)pa(1::size(a,dim=1)+1) !获取对角项
如果在子程序或者函数中,我们则需要为数组设置contiguous关键字
module diag_mod
implicit none
contains
function diag(a)result(ptr)
real,intent(in),target,contiguous::a(:,:) !需要加contiguous属性
real,pointer::ptr(:)
ptr(1:size(a))=>a
ptr=>ptr(1::size(a,dim=1)+1) !取对角项
end function diag
end module diag_mod
program main
use diag_mod
implicit none
real,target::a(10,10)
integer::i
real,pointer::p(:)
a=reshape([(i,i=1,100)],shape(a)) !使用reshape为数组赋初值
p=>diag(a) !使用指针获取对角项
write(*,*)p
p=[real::(i,i=111,120)] !修改对角项,此时p拿到的是对角项的引用,所以修改了之后,a的对角项也会改变
do i=1,10
write(*,*)a(i,i)
end do
end program main
contiguous属性对于数组的连续性做了强制要求,有时候可以使得编译器做出更好的优化,提高代码运行速度,因此在普通的含数组的过程中,也可以选择使用
思考题
- 如果传入的是数组的切片,那么还能用上述的方法修改吗
链表
此处我们只讨论最简单的单链表结构,其他更加复杂的数据结构读者可以自行编写
node的定义
将指针与结构体结合,就可以创建动态的数据结构
module node_mod
implicit none
type node_t
integer::x
type(node_t),pointer::next=>null()
end type node_t
end module node_mode
链表
可以一直为next指针分配内存,形成一个链,这样的数据结构称为链表
program main
use node_mod
implicit none
type(node_t),pointer::tail=>null()
type(node_t),target ::list
integer::i
list%x=0
tail=>list
do i=1,10
allocate(tail%next)!分配内存
tail=>tail%next !指向末尾
tail%x=i !赋值
end do
tail=>list
do
write(*,*)tail%x
if(.not.associated(tail%next))exit !如果tail%next没分配,代表到了链表的末尾
tail=>tail%next !指向下一个
end do
end program main
使用allocatable定义递归结构
需要注意的是,也也可以使用allocatable来创建这样的结构
type node_t
integer::x
type(node_t),allocatable::next
end type node_t
但是两者略有不同,当有两个变量type(node_t)::a,b执行a=b的操作时,对于pointer属性,a%next和b%next指向同一块内存,而对于allocatable属性a%next和b%next指向不同的内存
- 注:
gfortran在实现该功能的时候存在bug,所以均是指向同一块内存。ifort,ifx,flang没问题 - 通过重载赋值运算符
=,可以避免这个bug
module test
implicit none
type node_t
integer::x
type(node_t),pointer::next=>null()
end type node_t
type node_a
integer::x
type(node_a),allocatable::next
end type node_a
end module test
program main
use test
implicit none
type(node_t)::t,t1
type(node_a)::a,a1
t%x=1
allocate(t%next)
t%next%x=2
t1=t
write(*,*)t1%next%x
write(*,*)loc(t1%next),loc(t%next)!loc是编译器扩展语法,可以输出变量的地址,指针的地址相同
a%x=1
allocate(a%next)
a%next%x=2
a1=a
write(*,*)a1%next%x
write(*,*)loc(a1%next),loc(a%next)!可分配的地址不同
end program main
习题
- 尝试对链表实现插入操作
- (提高)尝试使用
allocatable实现一个单链表,并实现插入操作(提示:注意使用move_alloc) - (提高)使用自定义类型实现一个
list类型,并绑定append,insert,remove操作,并实现析构函数
Coarray
Coarray是Fortran原生支持的用于并行计算的结构,通过使用Coarray可以比较简单的写出并行计算的程序。
images
在Coarray中,每一个并行的最小单元称为image,Fortran中有两个内置函数this_image()和num_images()来获取当前的image和总的image的数量(image的编号是从1开始的)。
program main
implicit none
write(*,*)"this image=",this_image(),"num images",num_images()
end program main
需要使用这样的方式设置fpm
$ fpm run --compiler="caf" --runner="cafrun -n 4"
this image= 1 num images 4
this image= 3 num images 4
this image= 2 num images 4
this image= 4 num images 4
其中image的输出顺序并不确定,因为哪一个images先运行到write位置本身是不确定的。
codimension
如果需要在不同image之间进行交互,那就要引入codimension属性,用中括号表示。通过将一个变量引入该属性,他就获得了在不同的image之间交换数据的能力。
一些简单的定义如下
integer::a[*] !可以用于标量
integer,codimension(*)::b(10,10)!可以用于数组,可以使用codimension关键字
real,allocatable::c(:)[:] !可以用于可分配类型
type(submatrix):: a[*] !可以用于自定义类型
complex(8)::a(10,10)[2,2:3,*] !也可以设置多维的,自定义边界
allocate(c(10)[*])
如果是可分配的,分配的时候必须分配为[*],这是因为实际的image的数量是在运行的时候设置的,编译的时候并不确定。
运算
如果直接对一个变量进行赋值,那么表示对所有image都赋值。如果添加了[]则表示对指定的image赋值
program main
implicit none
integer::me[*]
me=3
write(*,*)this_image(),"me1=",me
me[2]=100
me[3]=me[4]+7
write(*,*)this_image(),"me2=",me
end program main
1 me1= 3
2 me1= 3
2 me2= 100
3 me1= 3
3 me2= 10
4 me1= 3
4 me2= 3
1 me2= 3
me[2:3]=[4,5]这样的语法是不合法的- 可以用
me=this_image()为不同image设置存在规律的不同的数。
同时我们还可以用if结构来控制当前执行哪个image.
if (this_images()==1)then
read(*,*)me
do i=2,nums_images()
me[i]=me
end do
end if
同步
此时我们在image 1中修改了其他image的值 ,如果此时不考虑在if后面添加输出,我们发现程序并没有按照我们的想法运行。
integer::z[*],i
if (this_images()==1)then
read(*,*)z
do i=2,nums_images()
z[i]=z
end do
end if
write(*,*)"image=",this_images(),z
我们读入10
image= 3 0
image= 4 0
image= 2 0
10
image= 1 10
这是因为,其他的image率先执行完毕了。所以此时我们需要对不同的image进行控制,此处就需要用到sync all,即所有的image都运行到此处时,程序再执行,提前运行到的先等待
integer::z[*],i
if (this_images()==1)then
read(*,*)z
do i=2,nums_images()
z[i]=z
end do
end if
sync all
write(*,*)"image=",this_images(),z
此时
2
image= 1 2
image= 2 2
image= 3 2
image= 4 2
同时,还有精确控制单个images的同步语句sync images(a),这里a可以时标量,也可以时一维数组,也可以是*,表示同步等待该线程。为了避免死锁,执行sync images()语句时,images Q 等待images P的次数
要和images P 等待images Q的次数相等。
事件(event)
Fortran2018中引入了event,可以更加优雅的控制不同的任务。每个image都可以通过event post发布一个事件,image可以通过event wait等待事件执行到当前位置之后,再继续执行。
! 代码取自 Milan Curcic/Modern Fortran
program push_notification
use iso_fortran_env, only: event_type
implicit none
type(event_type) :: notification[*]
if (num_images() /= 2) error stop &
'This program must be run on 2 images'
if (this_image() == 1) then
print *, 'Image', this_image(), 'working a long job'
call execute_command_line('sleep 5')
print *, 'Image', this_image(), 'done and notifying image 2'
event post(notification[2])
else
print *, 'Image', this_image(), 'waiting for image 1'
event wait(notification)
print *, 'Image', this_image(), 'notified from image 1'
end if
end program push_notification
$ fpm run --compiler="caf" --runner="cafrun -n 2"
Image 1 working a long job
Image 2 waiting for image 1
Image 1 done and notifying image 2
Image 2 notified from image 1
同时使用call event_query(event_var, count[, stat])子程序可以查询事件的发布次数。
coarray的内置函数
coarray 中提供了内置函数用于处理不同image之间的数据交换问题。
co_reduce
co_reduce可以表示对不同images的数据做归约操作,支持自定义运算(关于规约的定义,可以查看内置函数一节中,reduce函数的介绍)。
module pure_func_mod
implicit none
contains
pure real function pow_add(a,b)result(c)
real,intent(in)::a,b
c=sqrt(a**2+b**2)
end function pow_add
end module pure_func_mod
program main
use pure_func_mod,only:pow_add
implicit none
real::a[*]
a=this_image()
call co_reduce(a,pow_add)
write(*,*)this_image(),a
end program main
其中的operation是一个自定义的函数,且必须是纯函数
$ fpm run --compiler="caf" --runner="cafrun -n 4"
3 5.47722578
4 5.47722578
1 5.47722578
2 5.47722578
同时co_reduce还支持result_images选项,表示只将结果输出到对应的imgaes
- 练习:编写函数
f(a,b)=lcm(a,b),将结果输出到编号为2的image, 并验证结果是否正确,此处lcm指的是最小公倍数。
同时直接提供了使用较多的几类函数co_max,co_min,co_sum,不需要自行编写函数。
co_broadcast
这是广播函数,用于将对应image的值广播到所有的image上
program main
use pure_func_mod,only:pow_add
implicit none
real::a[*]
if(this_image()==1)then
read(*,*)a
end if
call co_broadcast(a, source_image=1)
write(*,*)this_image(),a
end program main
10
4 10.0000000
1 10.0000000
2 10.0000000
3 10.0000000
team 分组并行
有时候我们需要为不同的image分配不同的任务,此时team是一个简单的方式。
构建team
内置模块iso_fortran_env中定义了类型team_type,通过form team语句就可以为每个image分组,通过team_number函数可以查看当前的image属于哪一个team
program main
use iso_fortran_env
implicit none
type (team_type) :: myteam
integer ::teamid,id,np
id=this_image()
np=num_images()
teamid=1
if(id > np/2)teamid=2
form team(teamid,myteam)
write(*,*)"this image=",id,"team number",team_number(myteam)
end program main
$ fpm run --compiler="caf" --runner="cafrun -n 4"
this image= 3 team number 2
this image= 4 team number 2
this image= 1 team number 1
this image= 2 team number 1
$ fpm run --compiler="caf" --runner="cafrun -n 6"
this image= 6 team number 2
this image= 1 team number 1
this image= 2 team number 1
this image= 3 team number 1
this image= 4 team number 2
this image= 5 team number 2
team中进行计算
通过 change team语句可以将针对team进行计算,再该结构中**this_image()和num_images()对应的是各自team的编号,且内置函数计算的也是team内的结果**
program main
use iso_fortran_env
implicit none
type (team_type):: myteam
integer::teamid,id,np
real(8)::a[*]
id=this_image()
np=num_images()
teamid=1
if(id > np/2)teamid=2
a=id
form team(teamid,myteam)
change team(myteam)
call co_sum(a,result_image=1)
end team
write(*,*)"this image=",id,"team number",team_number(myteam),"a=",a
end program main
$ fpm run --compiler="caf" --runner="cafrun -n 4"
this image= 1 team number 1 a= 3.0000000000000000
this image= 2 team number 1 a= 2.0000000000000000
this image= 3 team number 2 a= 7.0000000000000000
this image= 4 team number 2 a= 4.0000000000000000
- 注意此时结果都在对应team的第一个image上
同时 change team还支持对不同的team执行不同的操作
如下是一个对不同image进行分组,然后在team1中使用矩形法,team2中使用梯形法求解 $$\int_0^{\pi} sin(x) dx = 2$$ 的例子
program main
use iso_fortran_env
implicit none
type(team_type)::myteam
real(8),parameter::pi=acos(-1.d0)
integer::teamid,i,id,np
real(8)::area,delta
integer,parameter::n=100
id=this_image()
np=num_images()
teamid=1
if(id > np/2)teamid=2
area=0
delta=pi/n
form team(teamid,myteam)
change team(myteam)
select case(team_number())
case(1)
do i=this_image(),n-1,num_images()
area=area+sin(i*delta)
end do
area=area*delta
call co_sum(area,result_image=1)
if(this_image()==1)write(*,*)"rect ",area
case(2)
do i=this_image(),n,num_images()
area=area+sin((i-0.5)*delta)
end do
area=area*delta
call co_sum(area,result_image=1)
if(this_image()==1)write(*,*)"trapz",area
end select
end team
end program main
$ fpm run --compiler="caf" --runner="cafrun -n 4"
trapz 2.0000822490709860
rect 1.9998355038874434
数据竞争
如果我们通过多个image同时对某一个image进行修改,此时会发生数据竞争。例如其他的image同时对image1进行累加操作,当同时有多个image想要执行该操作时,就会出现错误。
program main
implicit none
integer::id,np,i
integer::a[*]
id = this_image()
np = num_images()
a=0
do i = 1, np
a[i]=a[i]+1
end do
sync all
write(*,*)"this image=",id,"a",a
end program main
多次运行就会发现结果并不正确,也不相同
$ fpm run --compiler="caf" --runner="cafrun -n 4"
this image= 2 a 4
this image= 3 a 4
this image= 4 a 3
this image= 1 a 2
$ fpm run --compiler="caf" --runner="cafrun -n 4"
this image= 4 a 3
this image= 1 a 2
this image= 2 a 4
this image= 3 a 3
所以此处我们需要的a[i]=a[i]+1这条语句同时只能被一个image执行。
critical
通过critical块语句,可以直接保证在该区域只有一个image执行
program main
implicit none
integer::id,np,i
integer::a[*]
id = this_image()
np = num_images()
a=0
do i = 1, np
critical
a[i]=a[i]+1
end critical
end do
sync all
write(*,*)"this image=",id,"a",a
end program main
$ fpm run --compiler="caf" --runner="cafrun -n 4"
this image= 3 a 4
this image= 4 a 4
this image= 1 a 4
this image= 2 a 4
原子操作
Fortran内置函数中还提供了原子操作的函数,通过这些函数,可以实现上述功能
program main
implicit none
integer::id,np,i
integer::a[*]
id = this_image()
np = num_images()
a=0
do i = 1, np
call atomic_add(a[i],1)
end do
sync all
write(*,*)"this image=",id,"a",a
end program main
锁
使用lock语句也可以实现该功能
program main
use iso_fortran_env
implicit none
integer::id,np,i
integer::a[*]
type(lock_type)::lock_a[*]
id = this_image()
np = num_images()
a=0
do i = 1, np
lock(lock_a[i])
a[i]=a[i]+1
unlock(lock_a[i])
end do
sync all
write(*,*)"this image=",id,"a",a
end program main
- 使用
lock的时候要注意unlock
Fortran代码环境
program main
implicit none
write(*,*) "Hello Fortran"
end program
```fortran
program main
implicit none
write(*,*) "Hello Fortran"
end program
```
数学公式
费米子产生与湮灭算符的的反对易关系:\( [a_i, a_j^\dagger]_+ = \delta_{ij} \)
$$ \psi_i = \sum\limits_\mu C_{\mu i} \chi_\mu $$
费米子产生与湮灭算符的的反对易关系:\\( [a\_i, a\_j^\dagger]\_+ = \delta\_{ij} \\)
$$ \psi_i = \sum\limits_\mu C_{\mu i} \chi_\mu $$
注意下划线需要用\转义。